1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
| import { Route } from '@/types';
import { load } from 'cheerio';
import { parseDate } from '@/utils/parse-date';
import logger from '@/utils/logger';
import puppeteer from '@/utils/puppeteer';
import cache from '@/utils/cache';
export const route: Route = {
path: '/user/:userId',
categories: ['bbs'],
example: '/nodeseek/user/1',
parameters: { userId: '用户 ID,例如 1' },
features: {
requireConfig: false,
requirePuppeteer: true, // 启用 Puppeteer
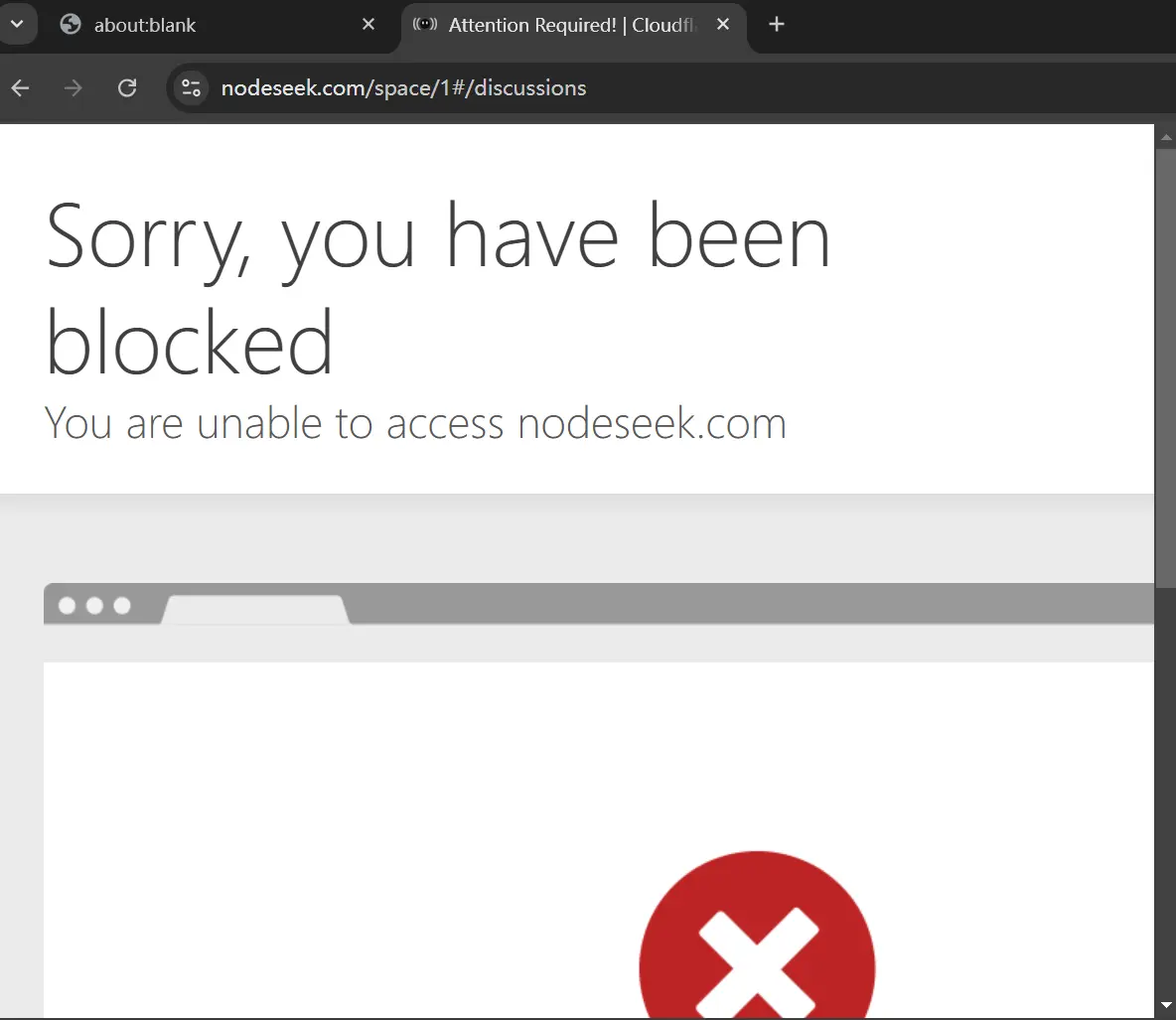
antiCrawler: true, // 启用反爬虫
supportBT: false,
supportPodcast: false,
supportScihub: false,
},
radar: [
{
source: ['nodeseek.com/space/:userId'],
target: '/user/:userId',
},
],
name: 'NodeSeek 用户话题',
maintainers: ['你的名字'],
handler: async (ctx) => {
const userId = ctx.req.param('userId');
const baseUrl = 'https://www.nodeseek.com';
const userUrl = `${baseUrl}/space/${userId}#/discussions`;
// 导入 puppeteer 工具类并初始化浏览器实例
const browser = await puppeteer();
// 打开一个新标签页
const page = await browser.newPage();
// 设置请求头
await page.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
});
// 访问目标链接
logger.http(`Requesting ${userUrl}`);
await page.goto(userUrl, {
waitUntil: 'networkidle2', // 等待页面完全加载
});
// 模拟滚动页面(如果需要)
await page.evaluate(() => {
window.scrollBy(0, window.innerHeight);
});
// 等待帖子列表加载
await page.waitForSelector('a[href^="/post-"]', { timeout: 7000 });
// 获取页面的 HTML 内容
const response = await page.content();
const $ = load(response);
// 提取帖子列表
let items = $('a[href^="/post-"]')
.toArray()
.map((item) => {
const $item = $(item);
const title = $item.find('span').text().trim();
const link = `${baseUrl}${$item.attr('href')}`;
return {
title,
link,
};
});
// 排除页脚的两个固定链接
const excludedLinks = ['/post-6797-1', '/post-6800-1'];
items = items.filter((item) => !excludedLinks.includes(new URL(item.link).pathname));
// 最多提取 15 个帖子
items = items.slice(0, 15);
// 打印提取的帖子列表
console.log('提取的帖子列表:', items); // 调试信息
// 如果帖子列表为空,可能是页面未加载动态内容
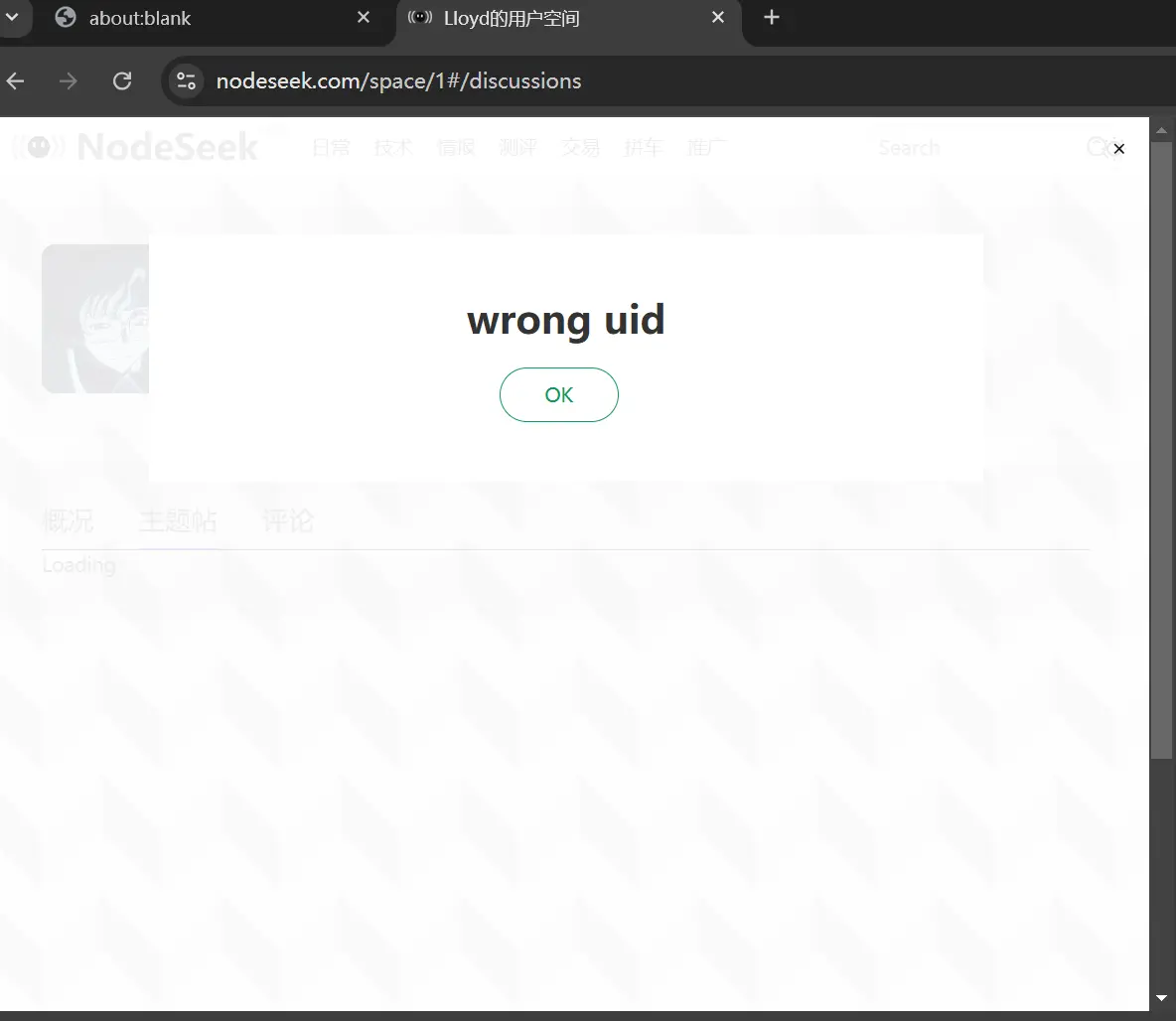
if (items.length === 0) {
throw new Error('无法获取帖子列表,请检查页面结构');
}
// 获取每个帖子的内容
items = await Promise.all(
items.map((item) =>
cache.tryGet(item.link, async () => {
// 打开一个新标签页
const postPage = await browser.newPage();
// 设置请求头
await postPage.setExtraHTTPHeaders({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
Referer: baseUrl,
});
// 访问帖子链接
logger.http(`Requesting ${item.link}`);
await postPage.goto(item.link, {
waitUntil: 'networkidle2', // 等待页面完全加载
});
// 获取帖子内容
const postHtml = await postPage.content();
const $post = load(postHtml);
item.description = $post('article.post-content').html();
item.pubDate = parseDate($post('time').attr('datetime'));
// 关闭帖子页面
await postPage.close();
return item;
})
)
);
// 关闭浏览器实例
await browser.close();
// 返回 RSS 数据
return {
title: `NodeSeek 用户 ${userId} 的话题`,
link: userUrl,
item: items,
};
},
};
|